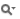|
STXXL
1.4.1
|
|
STXXL
1.4.1
|
This page gives an example of how an application using "traditional" containers and algorithms can be converted into using pipelines streaming.
The purpose of our example is to generate a huge random directed graph in a sorted edge array representation, i.e. the edges in the edge array must be sorted lexicographically. The definitions of the classes edge, random_edge and edge_cmp are in the following code listing.
A straightforward procedure to generate the graph is to: 1) generate a sequence of random edges, 2) sort the sequence, 3) remove duplicate edges from it. If we ignore definitions of helper classes the STL/STXXL code of the algorithm implementation is only five lines long:
Line 2 creates an STXXL external memory vector with 10 billion edges. Line 4 fills the vector with random edges (stxxl::generate from the STL is used). In the next line the STXXL external memory sorter sorts randomly generated edges using 512 megabytes of internal memory. The lexicographical order is defined by functor my_cmp, stxxl::sort also requires the comparison functor to provide upper and lower bounds for the elements being sorted. Line 8 deletes duplicate edges in the external memory vector with the help of the STL std::unique algorithm. The NewEnd vector iterator points to the right boundary of the range without duplicates. Finally (in the last line), we chop the vector at the NewEnd boundary.
Now we count the number of I/Os performed by this example: external vector construction takes no I/Os; filling with random values requires a scan — 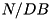 I/Os; sorting will take
I/Os; sorting will take 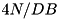 I/Os; duplicate removal needs no more than
I/Os; duplicate removal needs no more than 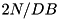 I/Os; chopping a vector is I/O-free. The total number of I/Os is
I/Os; chopping a vector is I/O-free. The total number of I/Os is 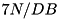 .
.
Now we "pipeline" the random graph generation example shown in the previous chapter. The data flow graph of the algorithm is presented in the following figure:
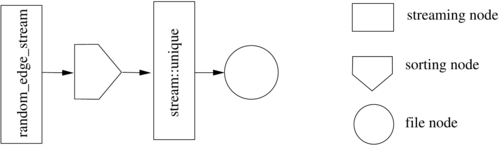
The following code listing shows the pipelined code of the algorithm, the definitions of edge, random_edge, and edge_cmp are assumed to be available from the listing in the previous section.
Since the sorter of the streaming layer accepts an stream input, we do not need to output the random edges. Rather, we generate them on the fly. The random_edge_stream object (model of stream) supplies the sorter with a stream of random edges. We define the type of the sorter node as sorted_stream; it is parameterized by the type of the input stream and the type of the comparison function object. Then a SortedStream object is created and its input is attached to the RandomStream object's output. The internal memory consumption of the sorter stream object is limited to 512 MB. The UniqueStream object filters the duplicates in its input edge stream. The generic stream::unique stream class stems from the STXXL library. The stream::materialize function records the content of the UniqueStream into the external memory vector. As in the previous non-pipelined version, we cut the vector at the NewEnd boundary.
Let us count the number of I/Os the program performs: random edge generation by RandomStream costs no I/O; sorting in SortedStream needs to store the sorted runs and read them again to merge — I/Os; UniqueStream deletes duplicates on the fly, it does not need any I/O; and materializing the final output can cost up to I/Os. All in all, the program only incurs 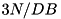 I/Os, compared to for the non-pipelined code.
I/Os, compared to for the non-pipelined code.
 1.8.5
1.8.5