|
STXXL
1.4-dev
|
|
STXXL
1.4-dev
|
The pipelined processing technique is very well known in the database world [51]. This page describes the abstract design of the stream package, see also Tutorial for the Stream Package.
Usually, the interface of an external memory algorithm assumes that it reads the input from (an) external memory container(s) and writes output into (an) external memory container(s). The idea of pipelining is to equip the external memory algorithms with a new interface that allows them to feed the output as a data stream directly to the algorithm that consumes the output, rather than writing it to the external memory first. Logically, the input of an external memory algorithm does not have to reside in the external memory, rather, it could be a data stream produced by another external memory algorithm.
Many external memory algorithms can be viewed as a data flow through a directed acyclic graph 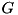 with node set
with node set 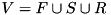 and edge set
and edge set 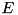 . The file nodes
. The file nodes 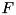 represent physical data sources and data sinks, which are stored on disks (e.g. in the external memory containers of the STL-user layer). A file node writes or/and reads one stream of elements. The streaming nodes
represent physical data sources and data sinks, which are stored on disks (e.g. in the external memory containers of the STL-user layer). A file node writes or/and reads one stream of elements. The streaming nodes 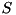 read zero, one or several streams and output zero, one or several new streams. Streaming nodes are equivalent to scan operations in non-pipelined external memory algorithms. The difference is that non-pipelined conventional scanning needs a linear number of I/Os, whereas streaming nodes usually do not perform any I/O, unless a node needs to access external memory data structures (stacks, priority queues, etc.). The sorting nodes
read zero, one or several streams and output zero, one or several new streams. Streaming nodes are equivalent to scan operations in non-pipelined external memory algorithms. The difference is that non-pipelined conventional scanning needs a linear number of I/Os, whereas streaming nodes usually do not perform any I/O, unless a node needs to access external memory data structures (stacks, priority queues, etc.). The sorting nodes 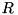 read a stream and output it in a sorted order. Edges in the graph denote the directions of data flow between nodes. The question "When is a pipelined execution of the computations in a data flow graph \f$ G \f$ possible in an I/O-efficient way?" is analyzed in [27].
read a stream and output it in a sorted order. Edges in the graph denote the directions of data flow between nodes. The question "When is a pipelined execution of the computations in a data flow graph \f$ G \f$ possible in an I/O-efficient way?" is analyzed in [27].
The streaming layer provides a framework for the pipelined processing of large sequences. Many external memory algorithms implemented with the STXXL streaming layer save a factor of at least two in I/Os. To the best of our knowledge we are the first who apply the pipelining method systematically in the domain of external memory algorithms. We introduce it in the context of an external memory software library.
In STXXL, all data flow node implementations have an stream interface which is similar to the STL Input iterators (Not be confused with the stream interface of the C++ iostream library.). As an input iterator, an stream object may be dereferenced to refer to some object and may be incremented to proceed to the next object in the stream. The reference obtained by dereferencing is read-only and must be convertible to the value_type of the stream. The concept of the stream also defines a boolean member function empty() which returns true iff the end of the stream is reached.
Now we tabulate the valid expressions and the expression semantics of the stream concept in the style of the STL documentation.
| Symbol | Semantics |
|---|---|
X, X1,...,Xn | A type that is a model of the stream |
T | The value type of X |
s, s1,...,sn | Object of type X, X1,...,Xn |
t | Object of type T |
| Name | Expression | Type requirements | Return type |
|---|---|---|---|
| Constructor | X s(s1,...,sn) | s1,....,sn are convertible to X1&,...,Xn& | |
| Dereference | *s | Convertible to T | |
| Member access | s->m | T is a type for which t.m is defined | |
| Preincrement | ++s | X& | |
| End of stream check | (*s).empty() | bool |
| Name | Expression | Precondition | Semantics | Postcondition |
|---|---|---|---|---|
| Constructor | X s(s1,...,sn) | s1,...,sn are the n input streams of s | ||
| Dereference | *s | s is incrementable | ||
| Member access | s->m | s is incrementable | Equivalent to (*s).m | |
| Preincrement | ++s | s is incrementable | s is incrementable or past-the-end |
The binding of a stream object to its input streams (incoming edges in a data flow graph ) happens at compile time, i.e. statically. The other approach would be to allow binding at running time using the C++ virtual function mechanism. However this would result in a severe performance penalty because most C++ compilers are not able to inline virtual functions. To avoid this disadvantage, we follow the static binding approach using C++ templates. For example, assuming that streams s1,...,sn are already constructed, construction of stream s with constructor X::X(X1& s1,..., Xn& sn) will bind s to its inputs s1,...,sn.
After creating all node objects, the computation starts in a "lazy" fashion, first trying to evaluate the result of the topologically latest node. The node reads its intermediate input nodes, element by element, using the dereference and increment operator of the stream interface. The input nodes proceed in the same way, invoking the inputs needed to produce an output element. This process terminates when the result of the topologically latest node is computed. This style of pipelined execution scheduling is I/O efficient, it allows to keep the intermediate results in-memory without needing to store them in external memory.
The Streaming layer of the STXXL library offers generic classes which implement the functionality of sorting, file, and streaming nodes:
File nodes: Function streamify() serves as an adaptor that converts a range of ForwardIterators into a compatible stream. Since iterators of stxxl::vector are RandomAccessIterators, streamify() can be used to read external memory. The set of (overloaded) materialize functions implement data sink nodes, they flush the content of a STXXL stream object to an output iterator.
The library also offers specializations of streamify() and stream::materialize for stxxl::vector, which are more efficient than the generic implementations due to the support of overlapping between I/O and computation.
Sort nodes: The Stream layer sort class is a generic pipelined sorter which has the interface of an stream. The input of the sorter may be an object complying to the stream interface. As the STL-user layer sorter, the pipelined sorter is an implementation of parallel disk merge sort [26] that overlaps I/O and computation.
The implementation of stream::sort relies on two classes that encapsulate the two phases of the algorithm: sorted run formation (class runs_creator) and run merging (runs_merger). The separate use of these classes breaks the pipelined data flow: the runs_creator must read the entire input to compute the sorted runs. This facilitates an efficient implementation of loops and recursions: the input for the next iteration or recursion can be the sorted runs stored on disks ([39] [27]).
The templated class runs_creator has several specializations which have input interfaces different from the stream interface: a specialization where elements to be sorted are push_back'ed into the runs_creator object and a specialization that accepts a set of presorted sequences. All specializations are compatible with the runs_merger.
s1,...,sn and returns the result of a user-given n-ary function object functor(*s1,...,*sn) as the next element of the output stream until one of the input streams gets empty.As mentioned above, STXXL allows streaming nodes to have more than one output. In this case, only one output of a streaming node can have the stream interface (it is an iterator). The other outputs can be passed to other nodes using a "push-item" interface. Such an interface have file nodes (e.g. the method push_back of stxxl::vector) and sorting nodes (push_back-specializations). Streaming nodes do not have such methods by definition, however, it is always possible to reimplement all streaming nodes between sorting and/or file nodes as a single streaming node that will push_back the output elements to the corresponding sorting/file nodes.
 1.8.5
1.8.5 
