|
STXXL
1.4-dev
|
|
STXXL
1.4-dev
|
stxxl::map is an STL interface for search trees with unique keys. Our implementation of stxxl::map is a variant of a B+-tree data structure [13] supporting the operations insert, erase, find, lower_bound and upper_bound in optimal 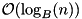 I/Os. Operations of stxxl::map use iterators to refer to the elements stored in the container, e.g.
I/Os. Operations of stxxl::map use iterators to refer to the elements stored in the container, e.g. find and insert return an iterator pointing to the data. Iterators are used for range queries: an iterator pointing to the smallest element in the range is returned by lower_bound, the element which is next to the maximum element in the range is returned by upper_bound. Scanning through the elements of the query can be done by using operator++ or operator-- of the obtained iterators in 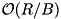 I/Os, where R is the number of elements in the result. Our current implementation does not exploit disk parallelism. The flexibility of the iterator-based access has some circumstances for an external memory implementation: iterators must return correct data after reorganizations in the data structure even when the pointed data is moved to a different external memory block.
I/Os, where R is the number of elements in the result. Our current implementation does not exploit disk parallelism. The flexibility of the iterator-based access has some circumstances for an external memory implementation: iterators must return correct data after reorganizations in the data structure even when the pointed data is moved to a different external memory block.
The way how iterators are used for accessing a stxxl::map is similar to the use of database cursors [45]. STXXL is the first C++ template library that provides an I/O-efficient search tree implementation with iterator-based access.
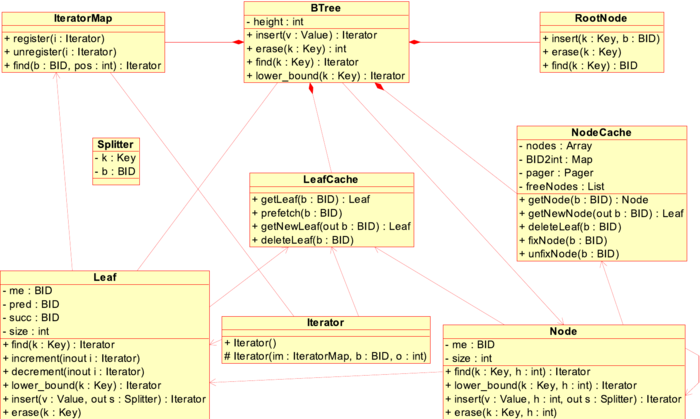
In the following we briefly describe the architecture of the STXXL B+-tree implementation. A simplified UML class diagram of the implementation is depicted in the figure below.
Our design allows to use different implementations for leaves and (internal) nodes. For example, leaves could be represented internally as sparse arrays [11] (currently, only the classic sorted array implementation is available). Leaves and nodes can have different external memory block sizes. Each leaf has links to the predecessor and successor leaves to speed up scanning. Our B+-tree is able to prefetch the neighbor leaves when scanning, obtaining a higher bandwidth by overlapping I/O and computation. The root node is always kept in the main memory and implemented as an std::map. To save I/Os, the most frequently used nodes and leaves are cached in corresponding node and leaf caches that are implemented in a single template class. An iterator keeps the block identifier (BID) of the external block where the pointed data element is contained, the offset of the data element in the block and a pointer to the B+-tree. In case of reorganizations of the data in external memory blocks (rebalancing, splitting, fusing blocks), all iterators pointing to the moved data have to be updated. For this purpose, the addresses of all instantiated iterators are kept in the iterator map object. The iterator map facilitates fast accounting of iterators, mapping BID and block offsets of iterators to its main memory addresses using an internal memory search tree. Therefore, the number of "alive" B+-tree iterators must be kept reasonably small. The parent pointers in leaves and nodes can be useful for finger search (The program can help the search tree finding an element by giving some "position close by" which was determined by an earlier search.) and insertions using a finger, however, that would require to store the whole B-tree path in the iterator data structure. This might make the iterator accounting very slow, therefore we do not maintain the parent links. The implementation can save I/Os when const_iterators are used: no flushing of supposedly changed data is needed (e.g. when scanning or doing other read-only operations). Our implementation of B+-tree supports bulk bottom-up construction from the presorted data given by an iterator range in 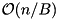 I/Os.
I/Os.
 1.8.5
1.8.5 
