|
STXXL
1.4.1
|
|
STXXL
1.4.1
|
Massive data sets arise naturally in many domains. Spatial databases of geographic information systems like GoogleEarth and NASA’s World Wind store terabytes of geographically referenced information that includes the whole Earth. In computer graphics one has to visualize highly complex scenes using only a conventional workstation with limited memory [31]. Billing systems of telecommunication companies evaluate terabytes of phone call log files [33]. One is interested in analyzing huge network instances like a web graph [28] or a phone call graph. Search engines like Google and Yahoo provide fast text search in their databases indexing billions of web pages. A precise simulation of the Earth’s climate needs to manipulate with petabytes of data [41]. These examples are only a sample of numerous applications that have to process vast amounts of data.
The internal memories of computers can keep only a small fraction of these large data sets. During the processing the applications need to access the external memory (e.g. hard disks) very frequently. One such access can be about 106 times slower than a main memory access. Therefore, the disk accesses (I/Os) become the main bottleneck.
The data are stored on the magnetic surface of a hard disk that rotates 4200–15,000 times per minute. In order to read or write a designated track of data, the disk controller moves the read/write arm to the position of this track (seek latency). If only a part of the track is needed, there is an additional rotational delay. The total time for such a disk access is an average of 3–10 ms for modern disks. The latency depends on the size and rotational speed of the disk and can hardly be reduced because of the mechanical nature of hard disk technology. After placing the read/write arm, the data are streamed at a high speed which is limited only by the surface data density and the MB bandwidth of the I/O interface. This speed is called sustained throughput and achieves up to 80 MB/s nowadays. In order to amortize the high seek latency, one reads or writes the data in blocks. The block size is balanced when the seek latency is a fraction of the sustained transfer time for the block. Good results show blocks containing a full track. For older low-density disks of the early 90s the track capacities were about 16–64 kB. Nowadays, disk tracks have a capacity of several megabytes.
Operating systems implement the virtual memory mechanism that extends the working space for applications, mapping an external memory file (page/swap file) to virtual addresses. This idea supports the Random Access Machine model [42] in which a program has an infinitely large main memory. With virtual memory the application does not know where its data are located: in the main memory or in the swap file. This abstraction does not have large running time penalties for simple sequential access patterns: the operating system is even able to predict them and to load the data in ahead. For more complicated patterns these remedies are not useful and even counterproductive: the swap file is accessed very frequently; the executable code can be swapped out in favor of unnecessary data; the swap file is highly fragmented and thus many random I/O operations are needed even for scanning.
The operating system cannot adapt to complicated access patterns of applications dealing with massive data sets. Therefore, there is a need for explicit handling of external memory accesses. The applications and their underlying algorithms and data structures should care about the pattern and the number of external memory accesses (I/Os) which they cause.
Several simple models have been introduced for designing I/O-efficient algorithms and data structures (also called external memory algorithms and data structures). The most popular and realistic model is the Parallel disk model (PDM) of Vitter and Shriver [55]. In this model, I/Os are handled explicitly by the application. An I/O operation transfers a block of B consecutive elements from/to a disk to amortize the latency. The application tries to transfer D blocks between the main memory of size M bytes and D independent disks in one I/O step to improve bandwidth, see figure below. The input size is N bytes which is (much) larger than M. The main complexity metrics of an I/O-efficient algorithm in PDM are the number of I/O steps (main metric) and the number of operations executed by the CPU. If not I/O but a slow internal CPU processing is the limiting factor of the performance of an application, we call such behavior CPU-bound.
The PDM has become the standard theoretical model for designing and analyzing I/O-efficient algorithms. For this model, the following matching upper and lower bounds for I/O complexity are known. Scanning a sequence of N items takes 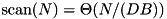 I/Os. Sorting a sequence of N items takes
I/Os. Sorting a sequence of N items takes 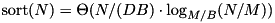 I/Os. Online search among N items takes
I/Os. Online search among N items takes 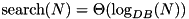 I/Os.
I/Os.
The PDM measures the transfers between the main memory and the hard disks, however, in modern architectures, the CPU does not access the main memory directly. There are a few levels of faster memory caches in-between (figure below): CPU registers, level one (L2), level two (L2) and even level three (L3) caches. The main memory is cheaper and slower than the caches. Cheap dynamic random access memory, used in the majority of computer systems, has an access latency up to 60 ns whereas L1 has a latency of less than a ns. However, for a streamed access a high bandwidth of several GB/s can be achieved. The discrepancy between the speed of CPUs and the latency of the lower hierarchy levels grows very quickly: the speed of processors is improved by about 55% yearly, the hard disk access latency only by 9% [47]. Therefore, the algorithms that are aware of the memory hierarchy will continue to benefit in the future and the development of such algorithms is an important trend in computer science.
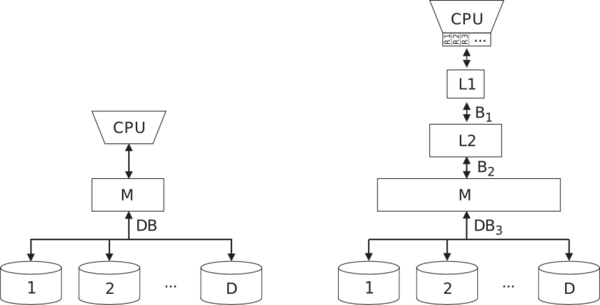
The PDM model only describes a single level in the hierarchy. An algorithm tuned to make a minimum number of I/Os between two particular levels could be I/O-inefficient on other levels. The cache-oblivious model in [32] avoids this problem by not providing the knowledge of the block size B and main memory size M to the algorithm. The benefit of such an algorithm is that it is I/O-efficient on all levels of the memory hierarchy across many systems without fine tuning for any particular real machine parameters. Many basic algorithms and data structures have been designed for this model ([32], [8], [11], [16]). A drawback of cache-oblivious algorithms playing a role in practice is that they are only asymptotically I/O-optimal. The constants hidden in the O-notation of their I/O-complexity are significantly larger than the constants of the corresponding I/O-efficient PDM algorithms (on a particular memory hierarchy level). For instance, a tuned cache-oblivious funnel sort implementation [23] is 2.6–4.0 times slower than our I/O-efficient sorter from STXXL (see Parallel Disk Sorting) for out-of-memory inputs [4]. A similar funnel sort implementation [17] is up to two times slower than the I/O-efficient sorter from the TPIE library for large inputs. The reason for this is that these I/O-efficient sorters are highly optimized to minimize the number of transfers between the main memory and the hard disks where the imbalance in the access latency is the largest. Cache-oblivious implementations tend to lose on the inputs, exceeding the main memory size, because they do (a constant factor) more I/Os at the last level of memory hierarchy. In this paper, we concentrate on extremely large out-of-memory inputs, therefore, we will design and implement algorithms and data structures efficient in the PDM.
Theoretically, I/O-efficient algorithms and data structures have been developed for many problem domains: graph algorithms, string processing, computational geometry, etc. (see the surveys [40], [56]). Some of them have been implemented: sorting, matrix multiplication ([53]), search trees ([22], [48], [6], [1]), priority queues ([15]), text processing ([24]). However, only few of the existing I/O-efficient algorithms have been studied experimentally. As new algorithmic results rely on previous ones, researchers, who would like to engineer practical implementations of their ideas and show the feasibility of external memory computation for the solved problem, need to invest much time in the careful design of unimplemented underlying external algorithms and data structures. Additionally, since I/O-efficient algorithms deal with hard disks, a good knowledge of low-level operating system issues is required when implementing details of I/O accesses and file system management. This delays the transfer of theoretical results into practical applications, which will have a tangible impact for industry. Therefore, one of the primary goals of algorithm engineering for large data sets is to create software frameworks and libraries that handle both the low-level I/O details efficiently and in an abstract way, and provide well-engineered and robust implementations of basic external memory algorithms and data structures.
The Standard Template Library (STL) [52] is a C++ library which is included in every C++ compiler distribution. It provides basic data structures (called containers) and algorithms. STL containers are generic and can store any built-in or user data type that supports some elementary operations (e.g. copying and assignment). STL algorithms are not bound to a particular container: an algorithm can be applied to any container that supports the operations required for this algorithm (e.g. random access to its elements). This flexibility significantly reduces the complexity of the library.
STL is based on the C++ template mechanism. The flexibility is supported using compile-time polymorphism rather than the object-oriented run-time polymorphism. The run-time polymorphism is implemented in languages like C++ with the help of virtual functions that usually cannot be inlined by C++ compilers. This results in a high per-element penalty of calling a virtual function. In contrast, modern C++ compilers minimize the abstraction penalty of STL inlining many functions.
STL containers include: std::vector (an unbounded array), std::priority queue, std::list, std::stack, std::deque, std::set, std::multiset (allows duplicate elements), std::map (allows mapping from one data item (a key) to another (a value)), std::multimap (allows duplicate keys), etc. Containers based on hashing (hash_set, hash_multiset, hash_map and hash_multimap) are not yet standardized and distributed as an STL extension.
Iterators are an important part of the STL library. An iterator is a kind of handle used to access items stored in data structures. Iterators offer the following operations: read/write the value pointed by the iterator, move to the next/previous element in the container, move forward/backward (random access) by some number of elements.
STL provides a large number of algorithms that perform scanning, searching, and sorting. The implementations accept iterators that possess a certain set of operations described above. Thus, the STL algorithms will work on any container with iterators following the requirements. To achieve flexibility, STL algorithms are parameterized with objects, overloading the function operator (operator()). Such objects are called functors. A functor can, for instance, define the sorting order for the STL sorting algorithm or keep the state information in functions passed to other functions. Since the type of the functor is a template parameter of an STL algorithm, the function operator does not need to be virtual and can easily be inlined by the compiler, thus avoiding the function call costs.
The STL library is well accepted and its generic approach and principles are followed in other famous C++ libraries like Boost [36] and CGAL [29].
Several external memory software library projects (LEDA-SM [25] and TPIE [9]) were started to reduce the gap between theory and practice in external memory computing. They offer frameworks that aim to speed up the process of implementing I/O-efficient algorithms, abstracting away the details of how I/O is performed. Those projects are excellent proofs of EM paradigm, but have some drawbacks which impede their practical use.
Therefore we started to develop STXXL library, which tries to avoid those obstacles. The objectives of STXXL project (distinguishing it from other libraries):
 1.8.5
1.8.5