|
STXXL
1.4.0
|
|
STXXL
1.4.0
|
STXXL is a layered library consisting of three layers (see following figure). The lowest layer, the Asynchronous I/O primitives layer (AIO layer), abstracts away the details of how asynchronous I/O is performed on a particular operating system. Other existing external memory algorithm libraries only rely on synchronous I/O APIs [25] or allow reading ahead sequences stored in a file using the POSIX asynchronous I/O API [9]. These libraries also rely on uncontrolled operating system I/O caching and buffering in order to overlap I/O and computation in some way. However, this approach has significant performance penalties for accesses without locality. Unfortunately, the asynchronous I/O APIs are very different for different operating systems (e.g. POSIX AIO and Win32 Overlapped I/O). Therefore, we have introduced the AIO layer to make porting STXXL easy. Porting the whole library to a different platform requires only reimplementing the AIO layer using native file access methods and/or native multithreading mechanisms.
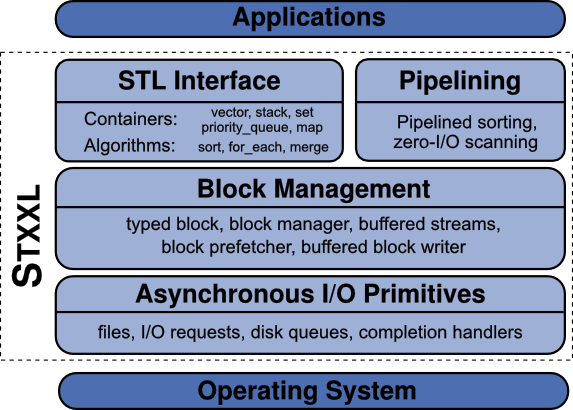
STXXL already has several implementations of the AIO layer which use different file access methods under POSIX/UNIX and Windows systems. Porting STXXL to Windows took only a few days. The main efforts were spent for writing the AIO layer using the native Windows calls. Rewriting the thread-related code was easy provided the Boost thread library; its interfaces are similar to POSIX threads. There were little header file and compiler-specific incompatibilities; those were solved by conditional compilation using the C++ preprocessor. The POSIX version of STXXL had run immediately on the all listed operating systems after changing some Linux-specific header file includes to more common POSIX headers.
The Block Management layer (BM layer) provides a programming interface emulating the parallel disk model. The BM layer provides an abstraction for a fundamental concept in the external memory algorithm design — a block of elements. The block manager implements block allocation/deallocation, allowing several block-to-disk assignment strategies: striping, randomized striping, randomized cycling, etc. The block management layer provides an implementation of parallel disk buffered writing [34], optimal prefetching [34], and block caching. The implementations are fully asynchronous and designed to explicitly support overlapping between I/O and computation.
The top of STXXL consists of two modules. The STL-user layer provides external memory sorting, external memory stack, external memory priority queue, etc. which have (almost) the same interfaces (including syntax and semantics) as their STL counterparts. The Streaming layer provides efficient support for pipelining external memory algorithms. Many external memory algorithms, implemented using this layer, can save a factor of 2–3 in I/Os. For example, the algorithms for external memory suffix array construction implemented with this module [27] require only 1/3 of the number of I/Os which must be performed by implementations that use conventional data structures and algorithms (either from STXXL STL-user layer, LEDA-SM, or TPIE). The win is due to an efficient interface that couples the input and the output of the algorithm–components (scans, sorts, etc.). The output from an algorithm is directly fed into another algorithm as input, without needing to store it on the disk in-between. This generic pipelining interface is the first of this kind for external memory algorithms.
The purpose of the AIO layer is to provide a unified approach to asynchronous I/O. The layer hides details of native asynchronous I/O interfaces of an operating system. Studying the patterns of I/O accesses of external memory algorithms and data structures, we have identified the following functionality that should be provided by the AIO layer:
The AIO layer exposes two user objects: stxxl::file and stxxl::request_ptr. Together with the I/O waiting functions stxxl::wait_all, stxxl::wait_any, and stxxl::poll_any they provide the functionality mentioned above. Using a stxxl::file object, the user can submit asynchronous read and asynchronous write requests (methods stxxl::file::aread and stxxl::file::awrite). These methods return a stxxl::request_ptr object which is used to track the status of the issued request. The AIO layer functions stxxl::wait_all, stxxl::wait_any, and stxxl::poll_any facilitate tracking a set of stxxl::request_ptr s. The last parameter of the methods stxxl::file::aread and stxxl::file::awrite is a reference to a callback function object (callback functor). The functor's operator()(request_ptr) method is called when the I/O request is completed.
As a part of the AIO layer, the STXXL library provides various I/O performance counters (stxxl::stats class). The class counts the number and the duration of the performed I/O operations as well as the transferred volume. Read and write operations are counted separately. STXXL also measures the time spent by the processing thread(s) waiting for the completions of I/Os (I/O wait time). This metric helps to evaluate the degree and the impact of overlapping between I/O and computation in an application.
The following listing shows a simple example of how to use AIO objects to perform asynchronous I/O. All STXXL library objects are defined in the namespace stxxl. For convenience, in line 1 we bring all names from the STXXL namespace to the local scope. In Line 8 a file object myfile is constructed. stxxl::syscall_file is an implementation of the STXXL stxxl::file interface which uses UNIX/POSIX read and write system calls to perform I/O. The file named "storage" in the current directory is opened in read-only mode. In line 9 an asynchronous read of the 1 MB region of the file starting at position 0 is issued. The data will be read into the array mybuffer. When the read operation is completed, my_handler::operator() will be called with a pointer to the completed request. The execution stops at line 11 waiting for the completion of the issued read operation. Note that the work done in the function do_something1() is overlapped with reading. When the I/O is finished, one can process the read buffer (line 12) and free it (line 13).
There are several implementation strategies for the STXXL AIO layer. Some asynchronous I/O related APIs (and underlying libraries implementing them) already exist. The most well known framework is POSIX AIO, which has an implementation on almost every UNIX/POSIX system. Its disadvantage is that it has only limited support for I/O completion event mechanism The Linux AIO kernel side implementation (http://freshmeat.net/projects/linux-aio/) of POSIX AIO does not have this deficit, but is not portable since it works under Linux only.
The STXXL AIO layer follows a different approach. It does not rely on any asynchronous I/O API. Instead we use synchronous I/O calls running asynchronously in separate threads. For each file there is one read and one write request queue and one thread. The main thread posts requests (invoking stxxl::file::aread() and stxxl::file::awrite() methods) to the file queues. The thread associated with the file executes the requests in FIFO order. This approach is very flexible and it does not suffer from limitations of native asynchronous APIs.
Our POSIX implementation of the AIO layer is based on POSIX threads and supports several Unix file access methods: the syscall method uses read and write system calls, the mmap method uses memory mapping (mmap and munmap calls), the sim_disk method simulates I/O timings of a hard disk provided a big internal memory. To avoid superfluous copying of data between the user and kernel buffer memory, the syscall method has the option to use unbuffered file system access. These file access methods can also be used for raw disk I/O, bypassing the file system. In this case, instead of files, raw device handles are open. The read/write calls using direct access (O_DIRECT option) have shown the best performance under Linux. The disadvantage of the mmap call is that programs using this method have less control over I/O: In most operating systems 4 KBytes data pages of a mmaped file region are brought to the main memory "lazily", only when they are accessed for the first time. This means if one mmaps a 100 KBytes block and touches only the first and the last element of the block then two I/Os are issued by the operating system. This will slow down many I/O-efficient algorithms, since for modern disks the seek time is much longer than the reading of 100 KBytes of contiguous data.
The POSIX implementation does not need to be ported to other UNIX compatible systems, since POSIX threads is the standard threading API on all POSIX-compatible operating systems.
Our Windows implementation is based on Boost threads, whose interfaces are very similar to POSIX threads.
AIO file and request implementation classes are derived from the generic stxxl::file and stxxl::request interface classes with C++ pure virtual functions. These functions are specialized for each access method in implementation classes to define the read, write, wait for I/O completion and other operations. The desired access method implementation for a file is chosen dynamically at running time. One can add the support of an additional access method (e.g. for a DAFS distributed filesystem) just providing classes implementing the stxxl::file and stxxl::request interfaces. We have decided to use the virtual function mechanism in the AIO layer because this mechanism is very flexible and will not sacrifice the performance of the library, since the virtual functions of the AIO layer need to be called only once per large chunk of data (i.e. B bytes). The inefficiencies of C++ virtual functions are well known. Similar to STL, the higher layers of STXXL do not rely on the running time polymorphism with virtual functions to avoid the high per-element penalties.
The Block-Management (BM) layer provides an implementation of the central concept in I/O efficient algorithms and data structures: a block of elements (stxxl::typed_block object). Besides, it includes a toolbox for allocating, deallocating, buffered writing, prefetching, and caching of blocks. The external memory manager (object stxxl::block_manager) is responsible for allocating and deallocating external memory space on disks. The manager supports four parallel disk allocation strategies: simple striping, fully randomized, simple randomized [12], and randomized cycling [54].
The BM layer also delivers a set of helper classes that efficiently implement frequently used sequential patterns of interaction with the (parallel disk) external memory. The optimal parallel disk queued writing [34] is implemented in the stxxl::buffered_writer class. The class operates on blocks. The stxxl::buf_ostream class is build on top of stxxl::buffered_writer and has a high level interface, similar to the interface of STL output iterators. Analogously, the classes stxxl::block_prefetcher and stxxl::buf_istream contain an implementation of an optimal parallel disk prefetching algorithm [34]. The helper objects of the BM layer support overlapping between I/O and computation, which means that they are able to perform I/O in the background, while the user thread is doing useful computations.
The BM layer views external memory as a set of large AIO files — one for each disk. We will refer to these files as disks. The other approach would be to map a related subset of blocks (e.g. those belonging to the same data structure) to a separate file. This approach has some performance problems. One of them is that since those (numerous) files are created dynamically, during the run of the program, the file system allocates the disk space on demand, that might in turn introduce severe uncontrolled disk space fragmentation. Therefore we have chosen the "one-large-file-per-disk" approach as our major scheme. However, the design of our library does not forbid data structures to store their content in separate user data files (e.g., as an option, stxxl::vector can be mapped to a user file).
The external memory manager (object stxxl::block_manager) is responsible for allocating and deallocating external memory space on the disks. The stxxl::block_manager reads information about available disks from the STXXL configuration file. This file contains the location of each disk file, the sizes of the disks, and the file access methods for each disk. When allocating a bunch of blocks, a programmer can specify how the blocks will be assigned to disks, passing an allocation strategy function object. The stxxl::block_manager implements the "first-fit" allocation heuristic [14]. When an application requests several blocks from a disk, the manager tries to allocate the blocks contiguously. This reduces the bulk access time.
On allocation requests, the stxxl::block_manager returns stxxl::BID objects – Block IDentifiers. An object of the type stxxl::BID describes the physical location of an allocated block, including the disk and offset of a region of storage on disk. One can load or store the data that resides at the location given by the stxxl::BID using asynchronous read and write methods of a stxxl::typed_block object.
The full signature of the STXXL "block of elements" class is stxxl::typed_block<RawSize,T,NRef,InfoType>. The C++ template parameter RawSize defines the total size of the block in bytes. Since block size is not a single global constant in the STXXL namespace, a programmer can simultaneously operate with several block types having different blocks sizes. Such flexibility is often required for good performance. For example, B+-tree leaves might have a size different from the size of the internal nodes. We have made the block size a template parameter and not a member variable for the sake of efficiency. The values of the template parameters are known to the compiler, therefore for the power of two values (a very common choice) it can replace many arithmetic operations, like divisions and multiplications, by more efficient binary shifts. A critical requirement for many external memory data structures is that a block must be able to store links to other blocks. An STXXL block can store NRef objects of type stxxl::BID. Additionally, one can equip a block with a field of the type InfoType, that can hold some per-block information. Block elements of type T can easily be accessed by the array operator [] and via random access iterators. The maximum number of elements available a block depends on the number of links and the sizes of T, InfoType and BID types. This number is accessible as stxxl::typed_block::size.
In the following listing, we give an example of how to program block I/O using objects of the BM layer. In line 2 we define the type of block: its size is one megabyte and the type of elements is double. The pointer to the only instance of the singleton object stxxl::block_manager is obtained in line 5. Line 6 asks the block manager to allocate 32 blocks in external memory. The new_blocks call writes the allocated BIDs to the output iterator, given by the last parameter. The std::back_inserter iterator adapter will insert the output BIDs at the end of the array bids. The manager assigns blocks to disks in a round-robin fashion as the striping() strategy suggests. Line 7 allocates 32 internal memory blocks. The internal memory allocator stxxl::new_alloc<block_type> of STXXL allocates blocks on a virtual memory page boundary, which is a requirement for unbuffered file access. Along lines 8–10 the elements of blocks are filled with some values. Then, the blocks are submitted for writing (lines 11-12). The request objects are stored in an std::vector for the further status tracking. As in the AIO example, I/O is overlapped with computations in the function do_something(). After the completion of all write requests (line 15) we perform some useful processing with the written data (function do_something1()). Finally we free the external memory space occupied by the 32 blocks (line 18).
The documentation of The STL-User Layer is on a separate subpage.
The Streaming layer provides efficient support for external memory algorithms with mostly sequential I/O pattern, i.e. scan, sort, merge, etc. A user algorithm, implemented using this module can save many I/Os. The win is due to an efficient interface, that couples the input and the output of the algorithms-components (scans, sorts, etc.). The output from an algorithm is directly fed into another algorithm as the input, without the need to store it on the disk.
Beyond the layered library, STXXL contains many small helpers commonly used in C++ like random numbers or shared pointers. See Common Utilities and Helpers for short descriptions.
 1.8.5
1.8.5 
